This RPIP is about how we want to define and select underperforming validators. It prioritizes a more complex, trustless on-chain mechanism instead of utilizing for example a simpler off-chain oDAO process. In exchange, it sacrifices a bit of precision: There will be (rare) cases of validators being exited that performed a bit better than others that do not get exited.
High level questions for the pDAO to consider:
Are we ok with this trade-off? You can explore how well the proposed metric tracks actual attestation performance for different values with this app.
Where do we want to draw the line for underperformance? As written, the RPIP aims for roughly 90% effectiveness, which would exit about 12% of validators that are responsible for roughly 70% of lost rewards, but this choice is definitely up for discussion. Since changing this target can be done with a pDAO settings change, we could also consider starting conservatively and make it more strict over time. Steely’s Dashboard has some excellent data that can be used to explore the current state of rocket pool validators.
There will be (rare) cases of validators being exited that performed a bit better than others that do not get exited.
Are we ok with this trade-off?
Yeah, sure. If you’re surfing along the cutoff point you can’t be pissed if it then hits you.
RPIP: “The initial threshold of 94% aims to exit people below 90% effectiveness with 95% sensitivity.”
Sounds ok to me too.
The only question I currently have is about the measurement duration. It would be harsh to exit as soon as you drop below the threshold for an hour. Then I would also answer the above questions differently.
The RPIP makes the example: “we would already be exiting people that are offline for 6% over a ~100 day window”
Does that mean that the performance would be measured as an average over 100 days? If yes, then great. Would also think it fair to use 2-4 weeks. So if shit happens and you need a couple weeks to get it working again there’s no worries, but if you need more than a month that’s on you.
Yes, as is the proposal would be based on performance over the last 100 days, the spec calls the setting performance_period.
I think the problem with making it much shorter is that being offline for a short amount of time would already get you kicked. E.g. if we use two weeks, being offline for 20 hours is enough.
First thank you knoshua, kane, samus, and all the other people who have worked on this.
So i think overall 90% is reasonable (and would probably be my choice), although 85% may be a more reasonable place to start. A 90% cutoff means that people will have to stay well above 90% on average to be safe from minor interruptions. i think 100 days is good. I also think that setting a goal of 90% with threat of exits would exit far fewer than 12%, as *many* NOs would self-regulate or self-exit before meeting punitive measures.
The counterpoint is that given the entry queue of ~120 days (60x2), exiting a node would essentially lose 33% of the years rewards, which is far higher than 90% over 100 days (~3% of yearly rewards). So you could factor in queue length in a way, although that presumably makes the proof more challenging. Obviously the length of staking matters, as losing 4 months of staking rewards while gaining a high performing NO for 10 years is probably worth it.
I think there could be a role for a strike system- a more stringent target, but only after the second episode in (lets say) 12 months would a node be exited. Or a probationary period where meeting the 90% cutoff puts you on probation where failing to meet 90% in any 30 day period for 12 periods would result in exit. Overall this gives a little leeway for folks who have a single failure that doesn’t repeat. In my work the folks who have multiple outages are highly likely to repeat, but there are a number of folks who have essentially flawless performance for years before going down; i’m not sure exiting these latter actually would necessarily improve rETH outcome because they are fairly likely to be high performers in the future.
I think that “absolute fairness” does not matter at all, as long as it is neutrally unfair, consistently applied, and relatively static. Here i think simplicity is much more important. If you set a rule ahead of time, people can argue it at the time, but it’s hard to be unhappy after the fact. We should be careful not to change the rules in the middle of a exit or for a given NO.
my major question is: what about the tail the other direction- ie, could a validator above 94% effectiveness be exited in certain situations?
That’s an interesting perspective. We want to reallocate staked ETH from underperformers to good performers to improve rETH yield, but the reallocation itself will temporarily hurt the yield, so we may want to try and time exits so that they line up with a short queue. In practice and with the proposed mechanism that could mean that we should decide the actual threshold as close to launch as possible, when we have a better idea of how long entry queue will be.
I’ll have to think about this one a bit more. Definitely seems doable technically. One implication of this would be that we are delaying underperformance exits at least a little bit. With the proposal as is, we would start exiting people as soon as the upgrade goes live, based on the performance of the 100 days prior to the upgrade.
With a strike system or similar, I think we would have to wait at least for another episode.
So just to clarify, in terms of effectiveness, the proposal is to taget 90%. The 94% is for the timeliness flag, which is just a proxy we would be using to allow the on-chain mechanism.
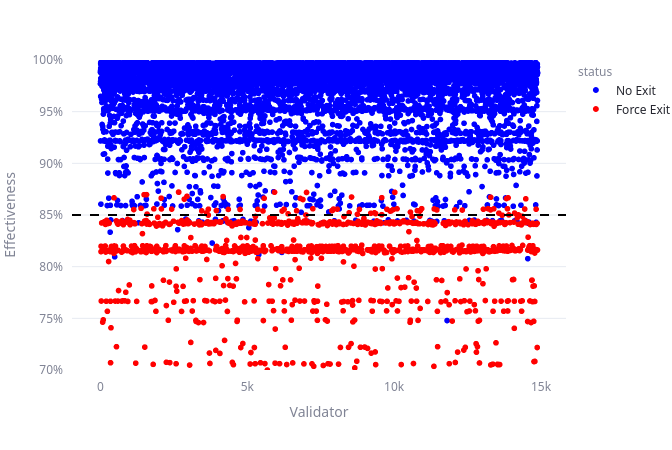
And yes, we should expect to mess up in both directions. The Exits Analysis App lets you explore this for different values and using historical minipool data.
For example, this is how it could look like if we are targeting 85% effectiveness. Red dots above the dashed line are validators that are above 85%, but would get exited. Blue dots below the dashed line are validators below 85% that don’t get exited:
I like the concept of a strike system or probation period or something similar that provides some allowance for moderate disruptions.
For example, I am pretty diligent at staying on top of my node maintenance and monitoring and usually run around 99%, but this past month my score has been dragged down by a power outage in my town that had my validator shut down for about a day. I also live in an area at risk of extended power outages from hurricanes, so every 3 years or so I would expect to have the validator down for 1-6 days while power infrastructure is being repaired. It would be nice to have some buffer to allow for these kind of infrequent events that are largely out of my control. It is hurricanes here, but other regions likely have similar infrequent but impactful disruptions from extreme weather events…
Being down for one day in a 30 day period is not close to getting you exited under this proposal. Being offline for 6 days consecutively is right at the threshold with the current numbers.
As far as a strike system or probation period, what is the advantage of that over just relaxing the exit threshold?
Yeah, that’s fair. Relaxing the exit criteria would be equivalent to a strike/probation system, and I assume much easier to implement.
Six days consecutive downtime would be pretty extreme…that would be disaster level damage…so if that is right on the edge of the performance exit threshold then I’m good.
This would address another long-standing source of frustration for the RP community about rETH performance. Underperforming nodes drag down the protocol average and its reputation.
I think we should target the most egregious offenders and not be too strict on selecting for maximum performance (as this is a centralizing force that drives towards data centers vs. home stakers.)
So, of the undesired outcomes, I think false positives (‘good performer - force exit’) should be avoided at all cost and are a worse outcome than false negatives (‘bad performer - no exit’). Playing around with the Exit Analysis App, reducing the target from 90% to 85% actually increases the false positives from 0 to 68. It’s not immediately clear to me why this is the case. Can you describe the underlying algorithm in general terms?
Alternatively, wouldn’t aggregating the smoothing pool performance data over X reward periods work for this purpose too?
Regarding the ‘6 days offline’ cutoff. Under ordinary circumstances, this would clearly be a disastrous outcome. But we have to remember we are dealing with home stakers here. What if, for example, someone goes on a 3-week holiday without node access, and the node unexpectedly goes down in the first week? Do we consider it acceptable the operator gets exited? Can we reasonably expect home stakers to not go on longer holidays without access to their node?
Definitely agree with the general sentiment of not wanting to be too strict. In the language of the proposal, less strict would mean a lower value for performance_threshold.
As far as false positives and false negatives as shown in the app: There is a “gold standard” for performance: share of maximal possible attestation rewards that were actually earned. And then there is another metric (share of timely target votes). The design uses the latter to approximate the former, because that’s something we can implement trustlessly with beacon state proofs. The app is about how well that approximation works.
So when you reduce the target to 85% from 90%, you are changing the definition of good and bad performer. Someone with 88% performance that gets exited in both cases goes from being a correct exit to a false positive.
I think the other slider (Sensitivity) controls the thing you want: lower sensitivity means our “test” misses more bad performers but exits less good performers. If you play around with it you should see that lower sensitivity gives a lower performance_treshold.
Yes, we’ve considered making this an oDAO duty. We wouldn’t need to approximate, but the sense is that we would like to avoid adding new (and in this case pretty powerful) oDAO duties, when we can come up with trustless alternatives.
Good question. There’s been some discussion about this on discord as well. I think it may be sensible to increase performance_period to 200 days, which then would make the offline cutoff 12 days.
There is also a trade-off here in that longer offline periods are pretty costly for rETH holders and that exiting validators can prevent further damage for both sides. It doesn’t seem like it at the moment, but long term having a validator exited hopefully isn’t permanent and the node operator that’s generally performing well can spin up a new one once they have their issue resolved.
Good point re: oDAO duties. We do want to go for a trustless solution if we can.
Ah, I see it now. The relationship between effectiveness target and sensitivity isn’t linear. E.g. with both at 90%, there are 0 good performers exited. But if you lower the effectiveness target to 85%, you have to lower sensitivity all the way to 74% to remain at 0 good performer exits. This means that if we make the effectiveness target less strict, we have to accept a relatively larger share of bad performers not exited.
Yeah, in the end we do have to draw a line somewhere. I think the rolling lookback window approach handles incidental downtimes elegantly if we choose the parameters well. One question I have is how we will deal with new nodes that don’t have a 100/200 day history yet. If we exclude them from evaluation entirely, it would take long time before the protocol can take action. But if we require 90% over their shorter lifespan, they would be under much more scrutiny than existing nodes. Maybe a ramp-up is needed there.
How long it takes to spin up a new validator depends on the RP queue as well as the Ethereum exit and entry queues. I don’t think we can make any sort of prediction how these will behave in the long term. Perhaps observed current queue lengths should factor in somewhere as well (although this probably makes more sense for liquidity exits than underperformance exits.)
So since the challenge mechanism works by claiming that certain epochs didn’t have a timely target attestation, we aren’t completely excluding new validators until they reach 100/200 days history. For example, if a new validator works fine for 2 days and then goes completely offline for 12 days, they could be exited based on those last epochs alone, independent of if the 188 days before the validator was online or not attesting at all.
On the other hand, if someone is online but slightly below what we consider acceptable performance, it will take close to the full 100/200 days for them to accumulate 12 days worth of missed epochs and be exited. So I think this ends up working out quite ok overall. In really problematic cases, we are able to act relatively quickly. But we also leave some room for newcomers to work through initial issues.
For underperformance, I think a RP queue is actually a reason to exit bad performers more aggressively. It means that we have other node operators ready to take over and hopefully do a better job. Exiting just to have ETH pile up in the deposit pool would not be great.
A long Beacon Chain queue is kind of the opposite. Exiting a bad performer and staking with another NO comes with the cost off the staked ETH not earning at all for ~2 months. It may make sense to lower the performance_threshold to start if queue is still long once Saturn 2 is launching.